
SparkException: Job aborted due to stage failure: exceeds max allowed : spark.rpc.message.maxSize


Problem: How to fix Spark serialized task failure — a guide on how to fix spark.rcp.message.maxsize
Apache Spark is one of the most popular distributed computing solutions for processing large amounts of data. However, while working with large amounts of data, you might face some errors that interfere with the execution of your Spark tasks.
For example, you might encounter the error “ SparkException: Job aborted due to stage failure: Serialized task xx:x was xxxxxxxxx bytes, which exceeds max allowed: spark.rpc.message.maxSize (268435456 bytes)
In this article, we’ll look at the causes of this error and how to solve it step by step.
Recognizing the Error: The error message indicates that the maximum size permitted by the configuration option spark.rpc.message.maxSize was exceeded by a particular serialized task in your Spark job. This parameter has a default value of 268435456 bytes (256 MB). Spark terminates a serialized task when it reaches this threshold, which results in the previously described error.
Finding the Solution: Increasing the spark.rpc.message.maxSize number at the cluster level, as opposed to the notebook level, is the necessary solution to this problem. This guarantees that the modification is applied to the whole Spark cluster. You can enable Spark to manage more complex serialized jobs without experiencing errors by modifying this value.
Step-by-Step Implementation:
Access the Cluster Configuration Page:
Open the ClusterUI for your Spark cluster.
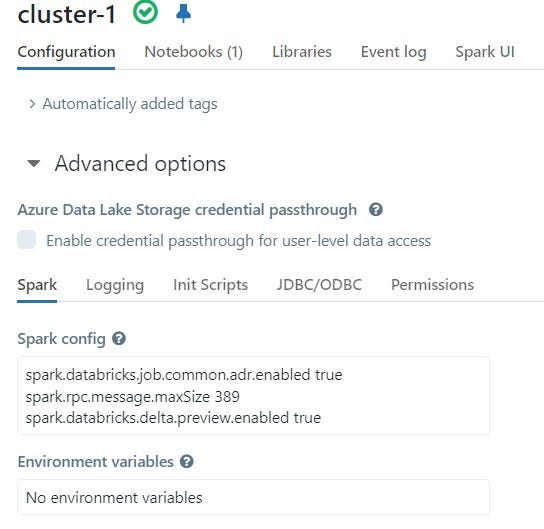
Navigate to the advanced options section in the cluster configuration page.
2. Modify Spark Configuration:
Locate the Spark Config section within the advanced options.
Add a new line specifying the desired
spark.rpc.message.maxSizevalue. For example:spark.rpc.message.maxSize 389sets the maximum size to 389 MB. Note: Make sure to choose a value greater than the serialized task size + buffer.PS: the error in Databricks notebook will mention the max size in bytes, but in the cluster configuration, you have to set the value in MBs.
Cluster configuration:
3. Restart the Cluster:
Save the modified configuration.
Restart the Spark cluster to apply the changes.
Validation and Successful Execution: After restarting the cluster, you can rerun your Spark jobs that previously encountered the “Serialized task” error. With the increased spark.rpc.message.maxSize, Spark will now be able to handle larger serialized tasks without aborting the job. Ensure that the updated configuration effectively resolves the issue and allows your Spark jobs to execute successfully.